| Hadoop完全分布搭建(这里以3台主机为例)+Hbase+Eclipse连接 | 您所在的位置:网站首页 › 如果不启动hadoop 则hbase完全无法使用 › Hadoop完全分布搭建(这里以3台主机为例)+Hbase+Eclipse连接 |
Hadoop完全分布搭建(这里以3台主机为例)+Hbase+Eclipse连接
|
一、网络配置 1.1网络配置(建议用管理员权限启动虚拟机,防止出现权限不足或者lock等问题) 1.11打开虚拟机点击安装好的centos系统
1.12点击虚拟机的编辑后选择虚拟网络编辑器
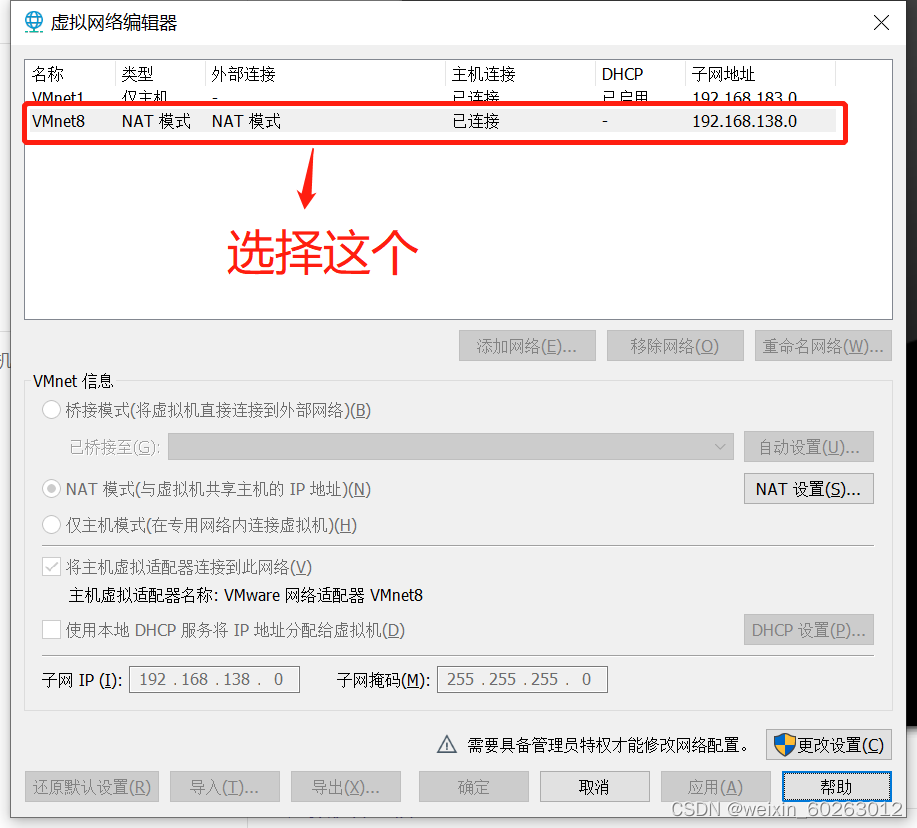
1.13点击VMnet8
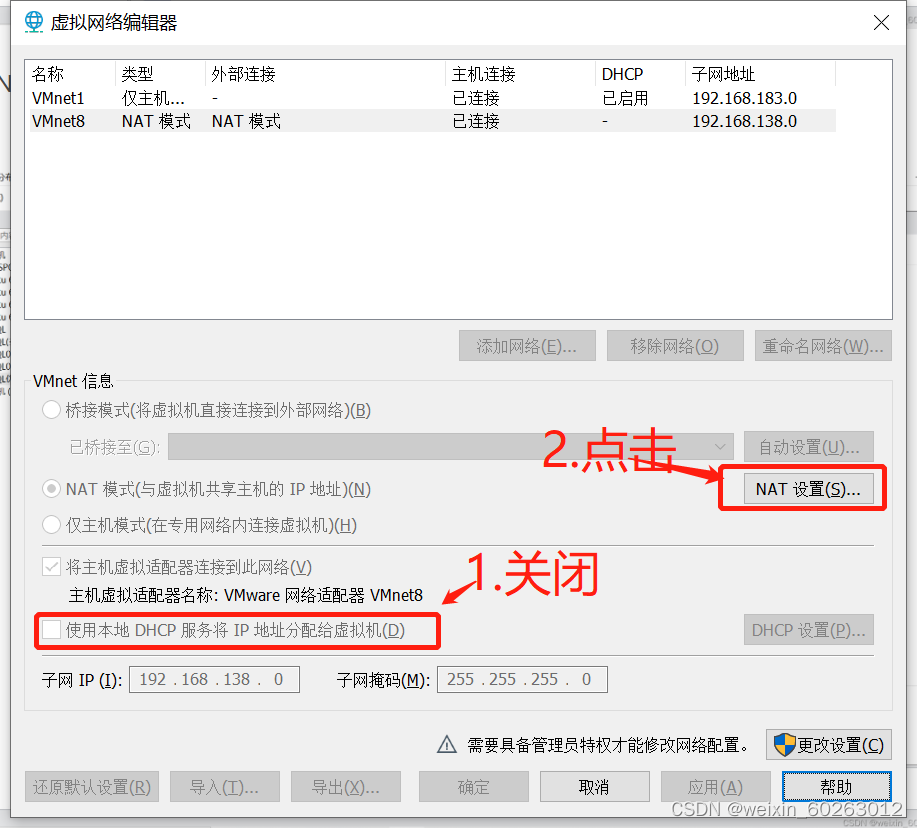
1.14点击NAT设置并关闭
1.15查看网关IP并记住(我这边是192.168.138.2)
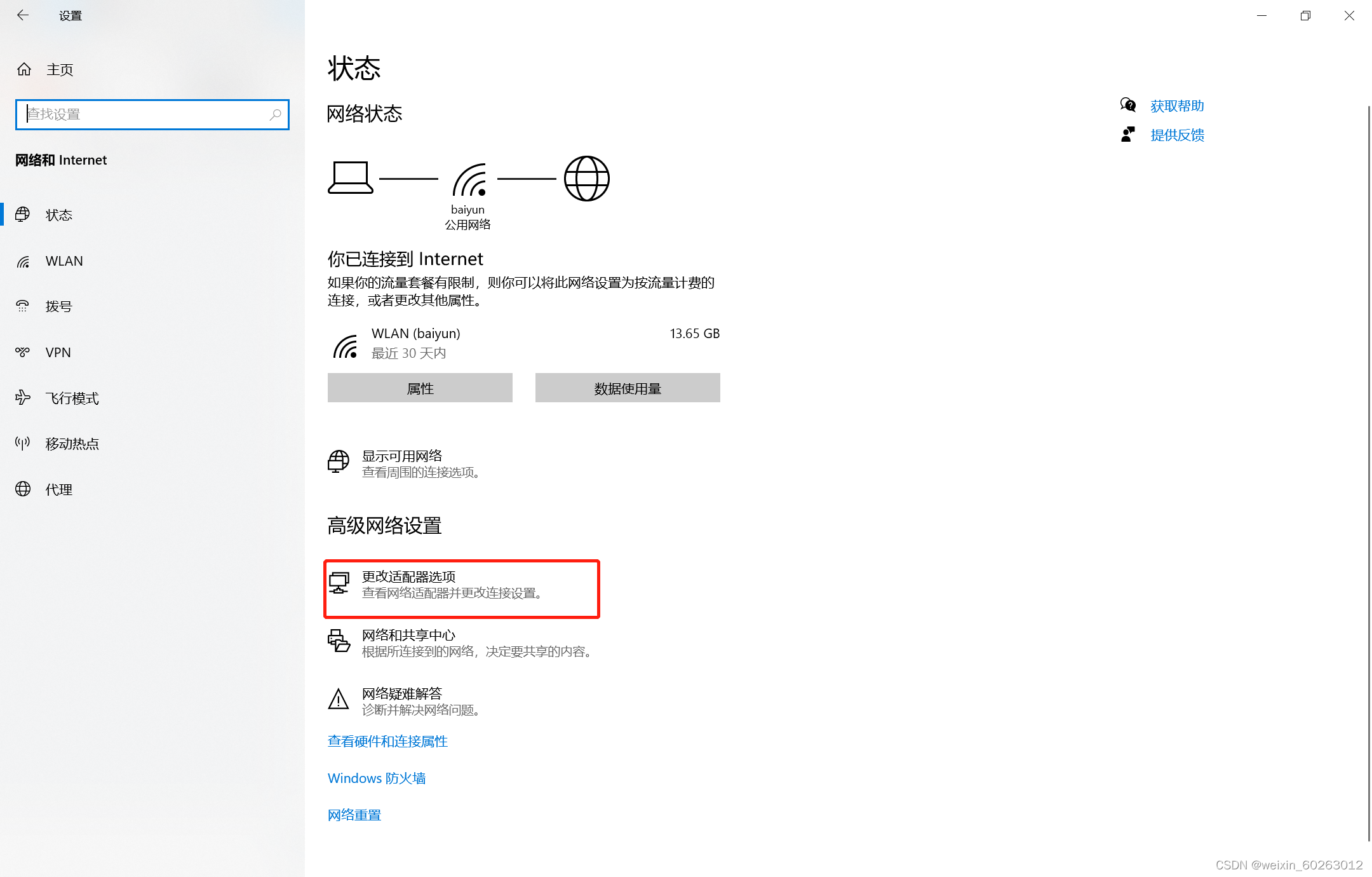
1.16打开主机网络点击更改设备选择器
1.17点击VMnet8后右键点击属性
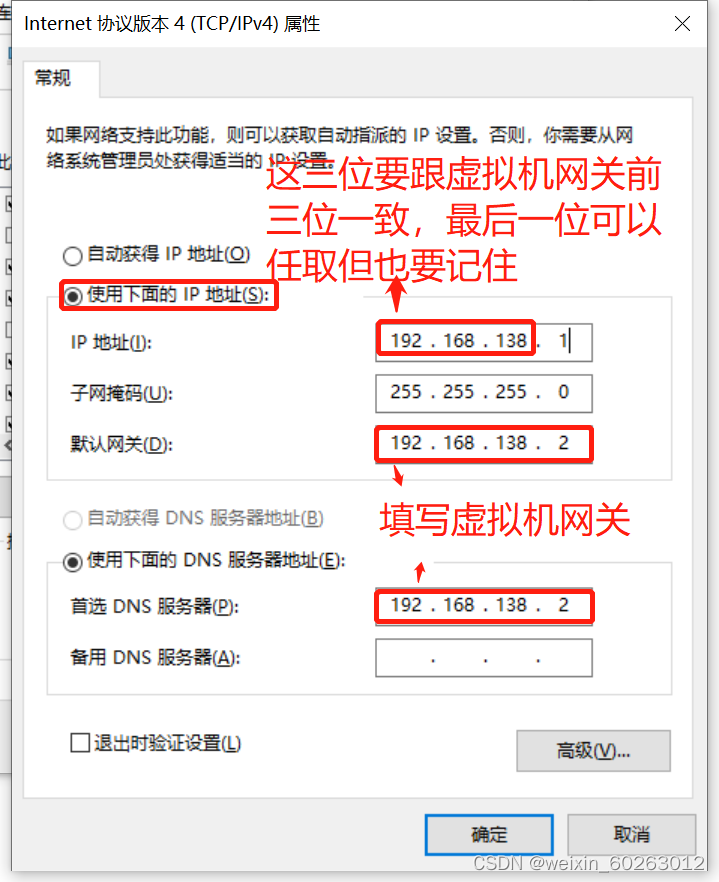
1.19 IP、网关配置(配置完网络环境后千万不要去共享网络不然xshell和xftp到时候连接不上虚拟机系统。)
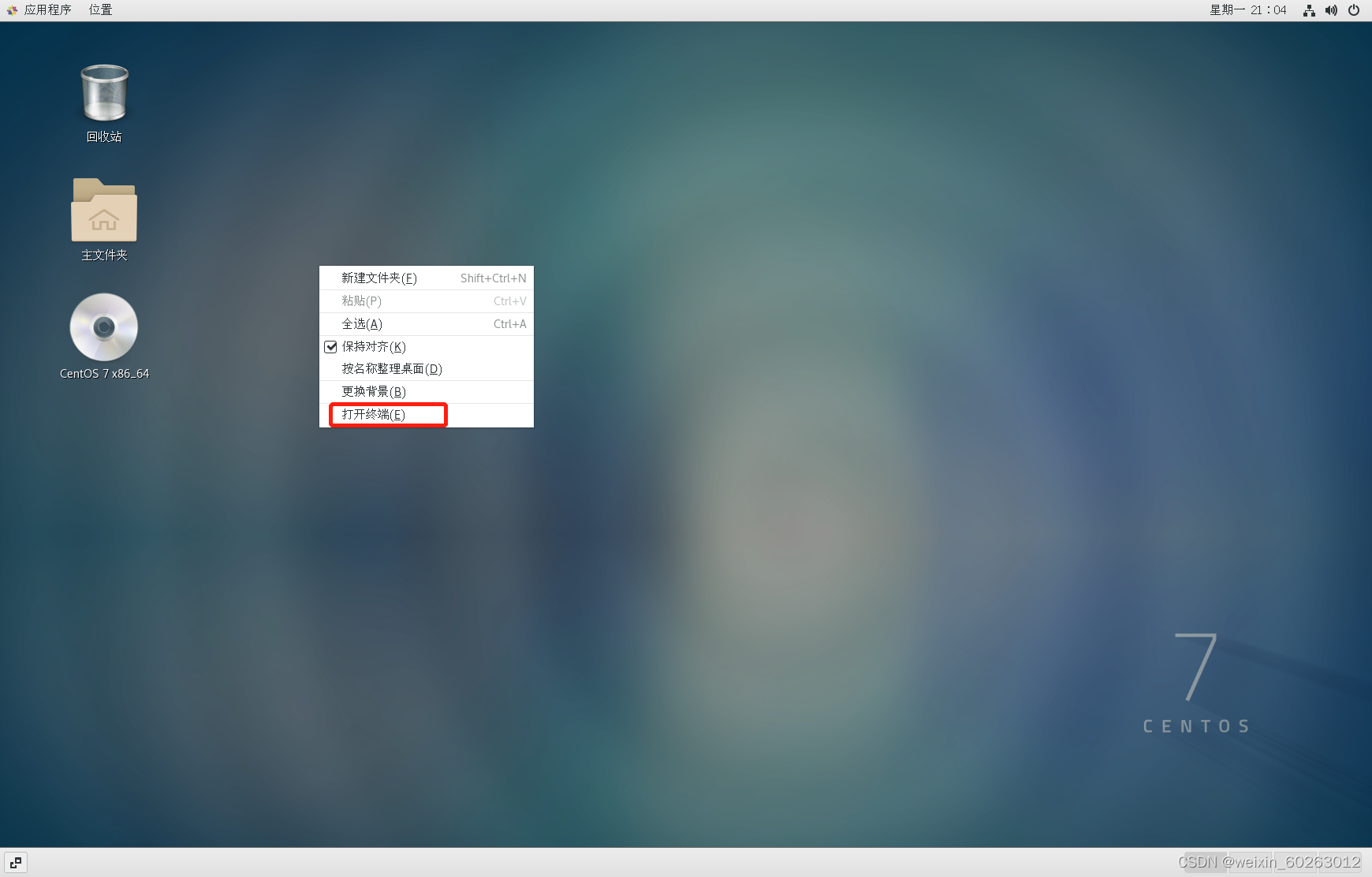
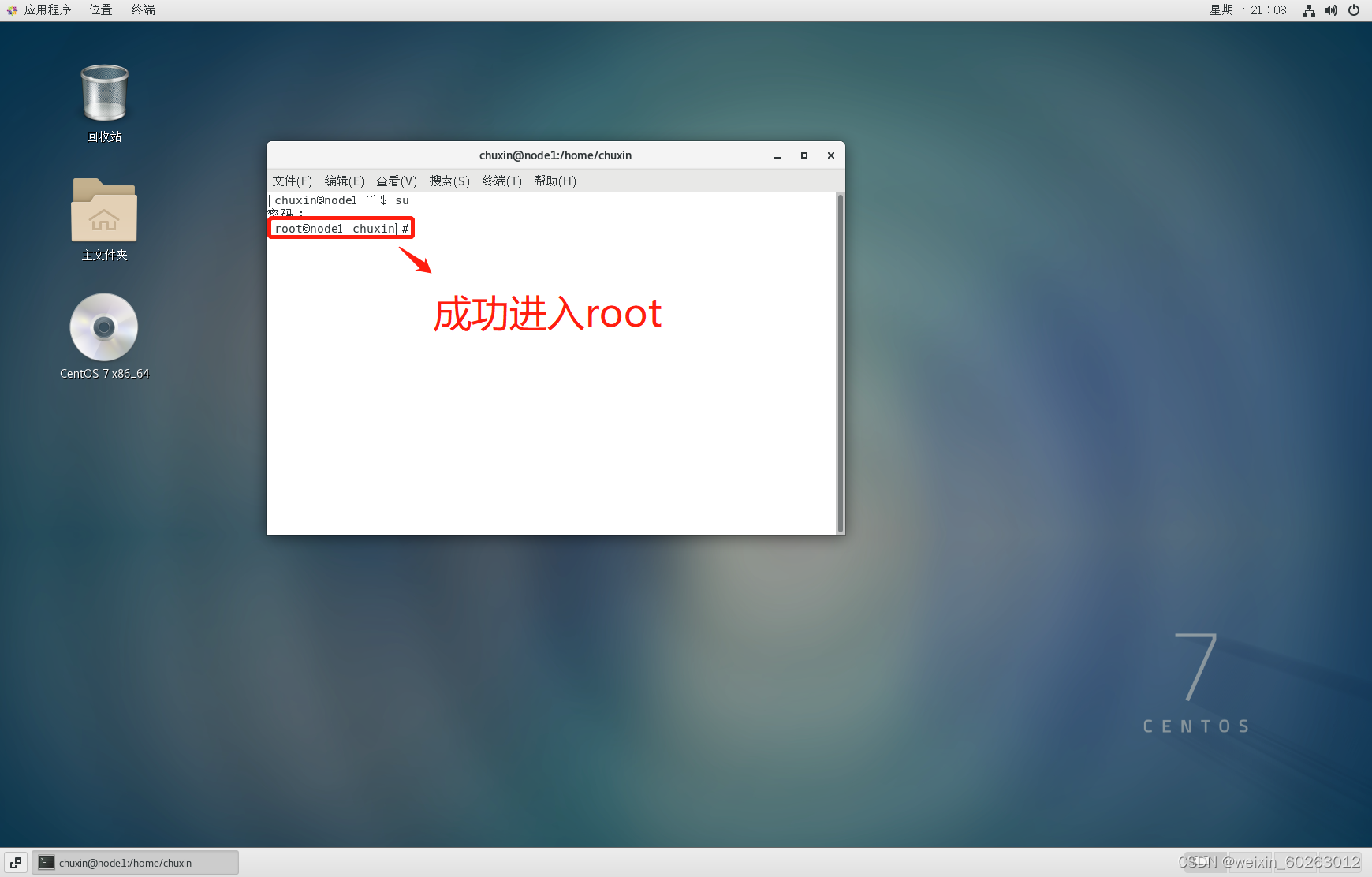
1.2启动centos系统,进行centos网络配置 1.21右键桌面打开终端,输入su指令按Enter键后输入密码进入root用户(为了更好的完成下面配置)
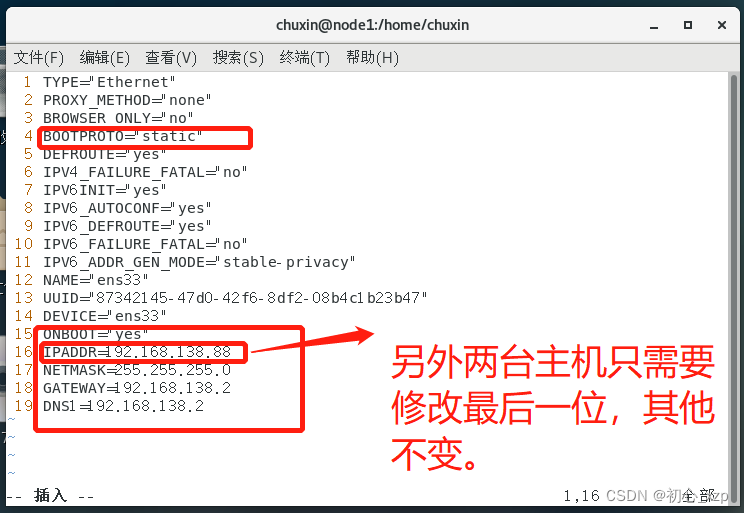
1.22进入网络配置文件 vim /etc/sysconfig/network-scripts/ifcfg-ens33
把BOOTPROTO修改为static ONBOOT修改为yes 添加(IPADDR前三位要跟虚拟机网关一致,NETMASK跟主机网络配置一致,GATEWAY,DNS1填写虚拟机网关,如果不配做DNS1会出现ping不通域名) 这里以虚拟网关为192.168.138.2为例子进行配置,每台机的虚拟机网关都不一样,请勿完全照搬! IPADDR=192.168.138.88 NETMASK=255.255.255.0 GATEWAY=192.168.138.2 DNS1=192.168.138.2
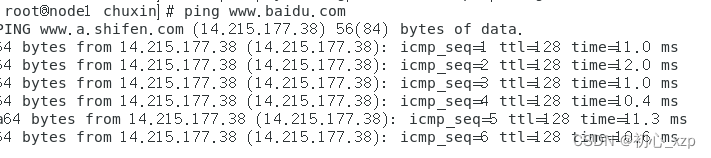
配置完后重启网络 重启网络 service network restart另外两台主机网络配置方法与上面相同。 1.23测试网络(先把防火墙关了) 关闭防火墙命令 systemctl stop firewalld.service查看防火墙状态 systemctl status firewalld.service测试 ping www.baidu.com
使用Ctrl+Z停止ping百度 主机ping虚拟机(如果ping不通很大可能是虚拟机防火墙未关闭)
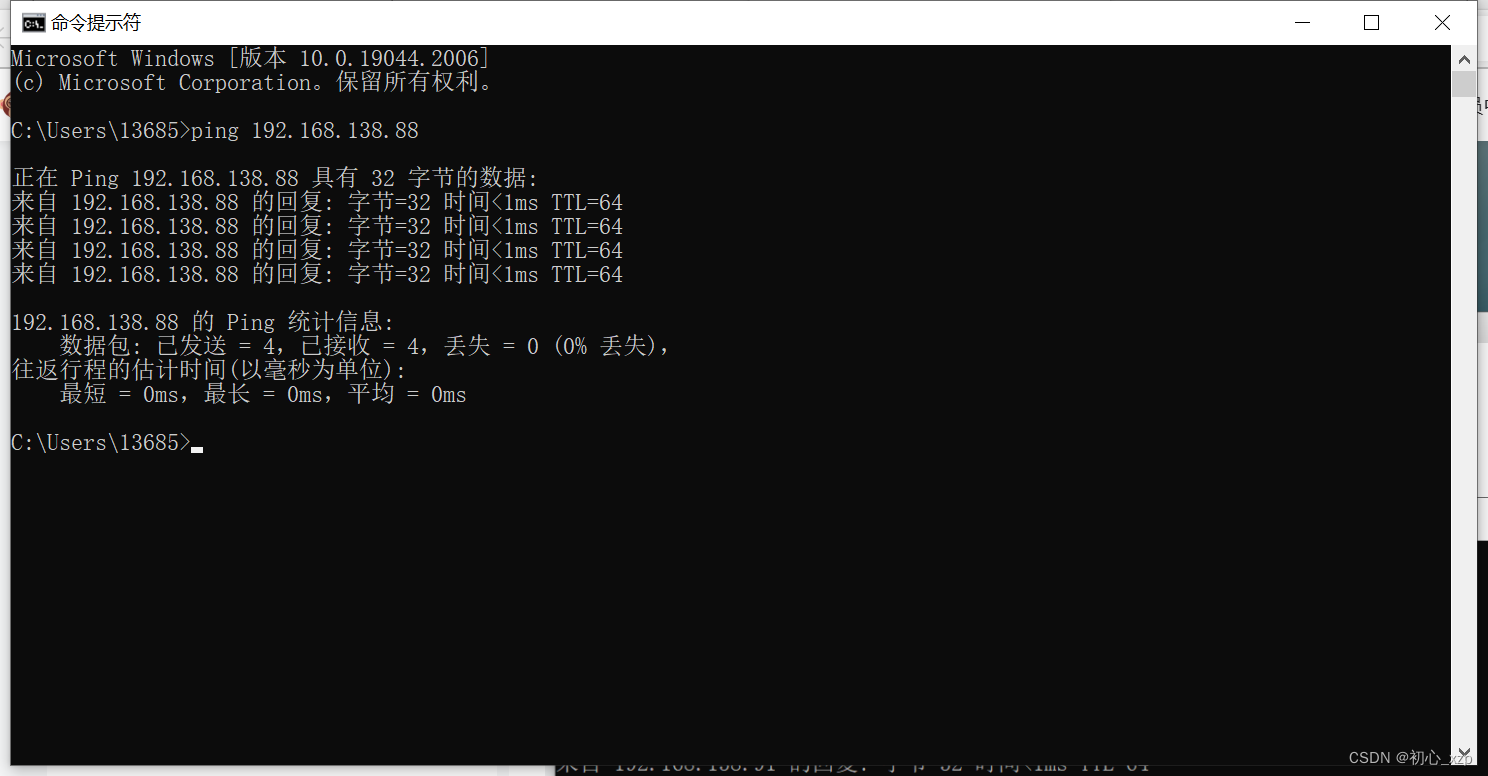
虚拟机ping主机(如果ping不通主机IP很大可能是主机防火墙未关闭)
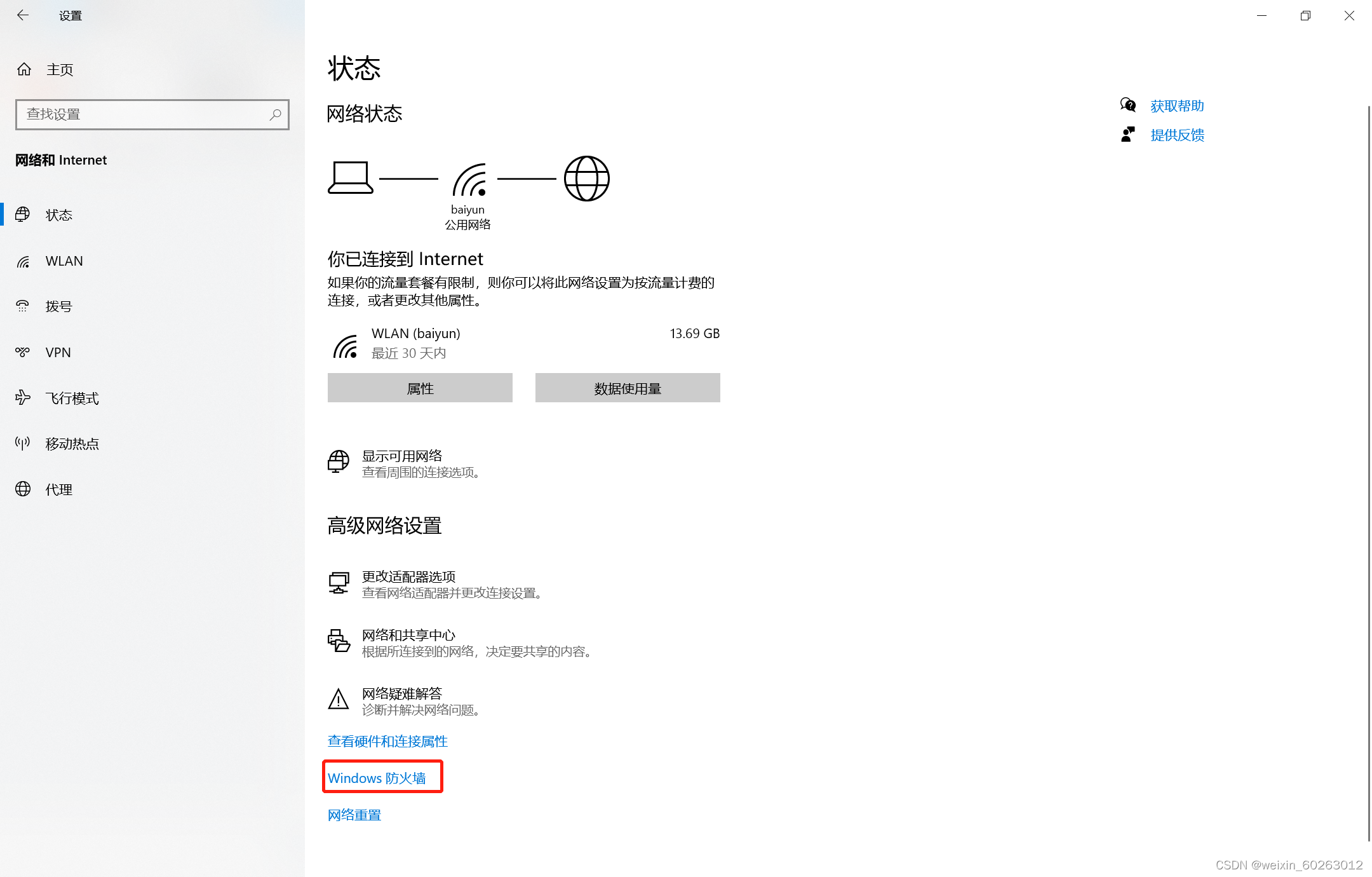
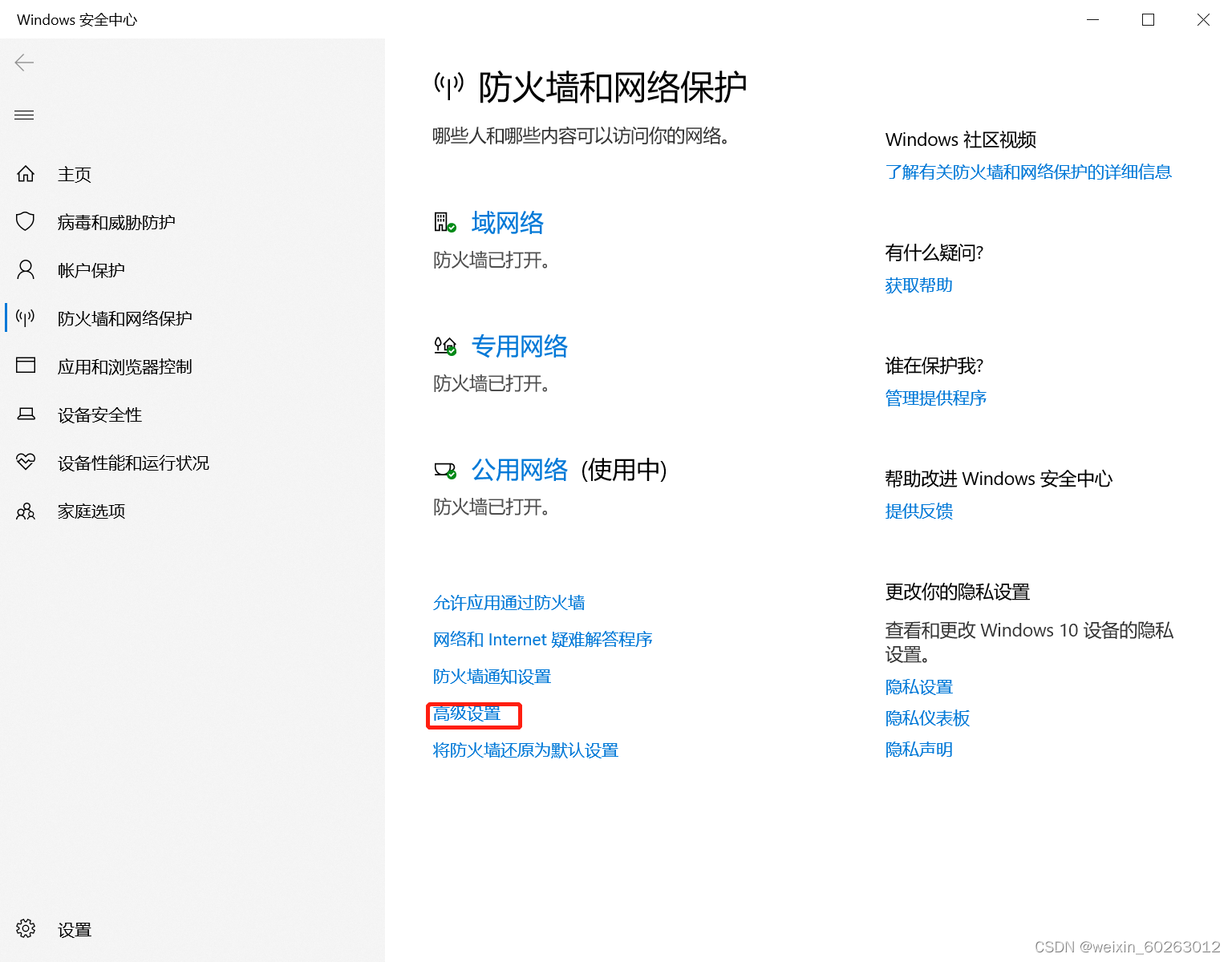
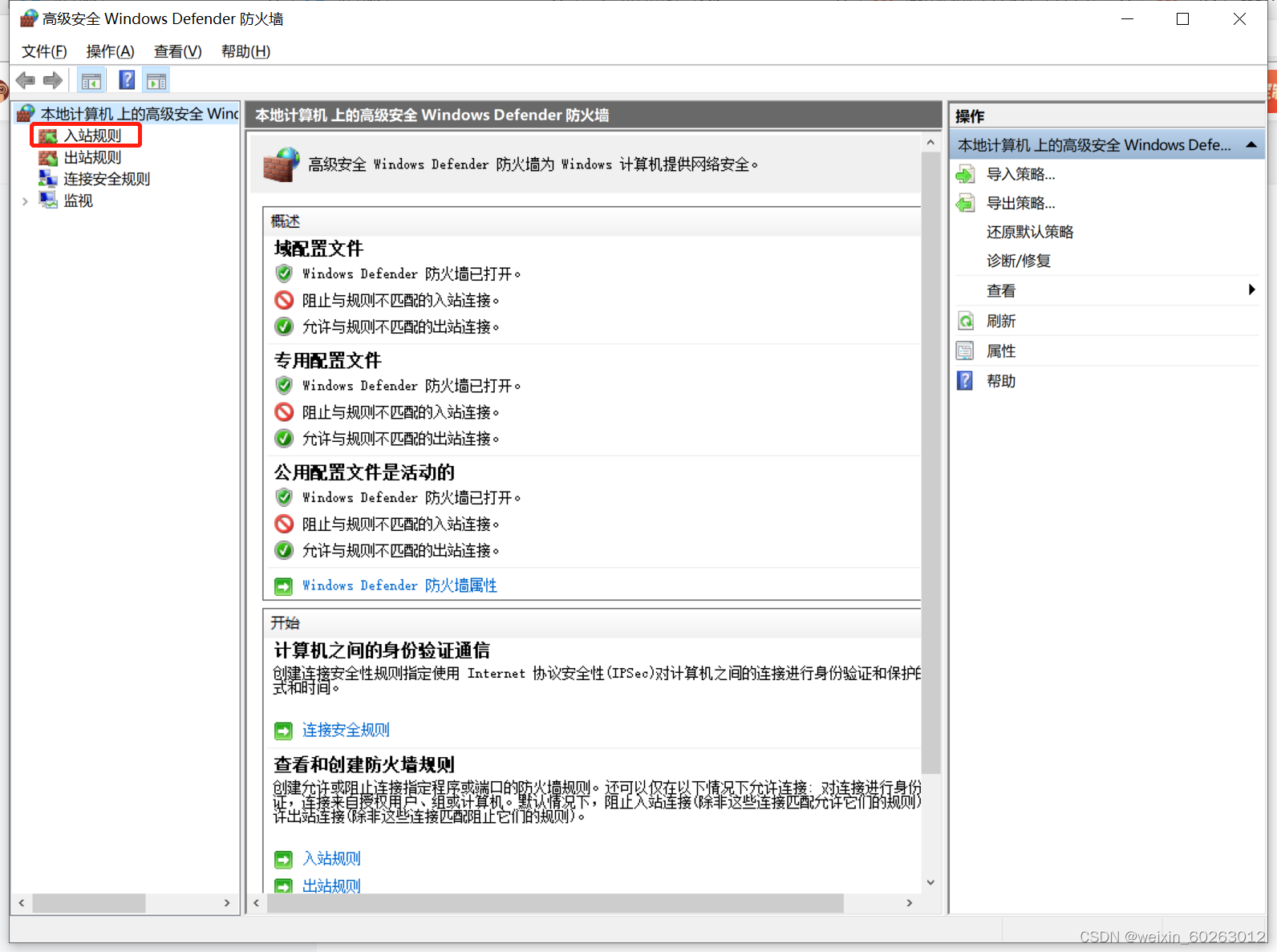
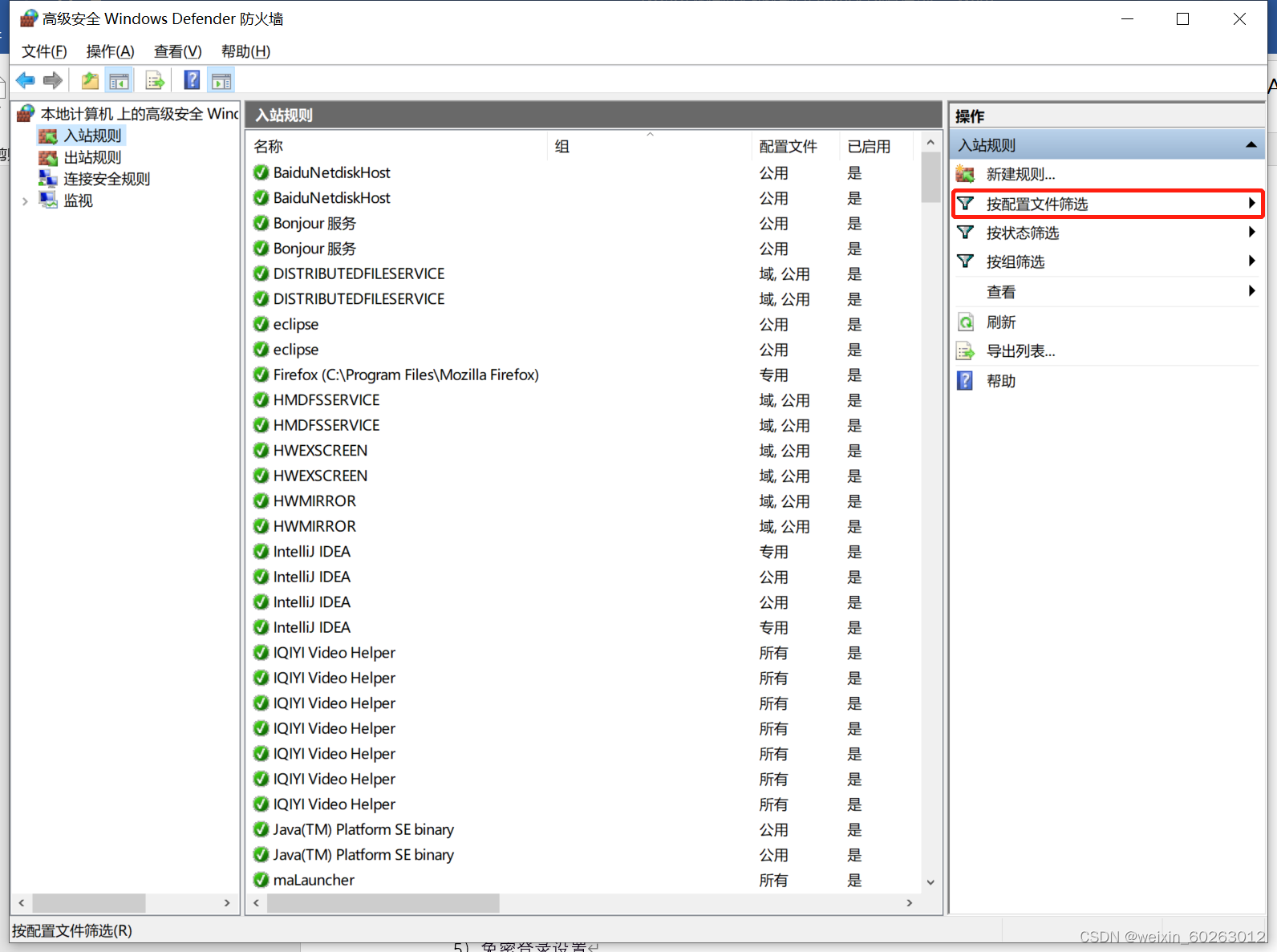
使用Ctrl+Z停止ping主机IP 如果没有事先准备好另外两台虚拟机则可以用这台虚拟机进行克隆然后修改IP。 1.24解决虚拟机ping不通主机IP方法 打开主机网络打开防火墙选择高级设置点击入站规则点击按配置文件筛选后选择按公用配置文件筛选找到(回显请求 – ICMPv4-In)改为允许。
二、压缩包准备(百度网盘提取码1221) 压缩包下载链接
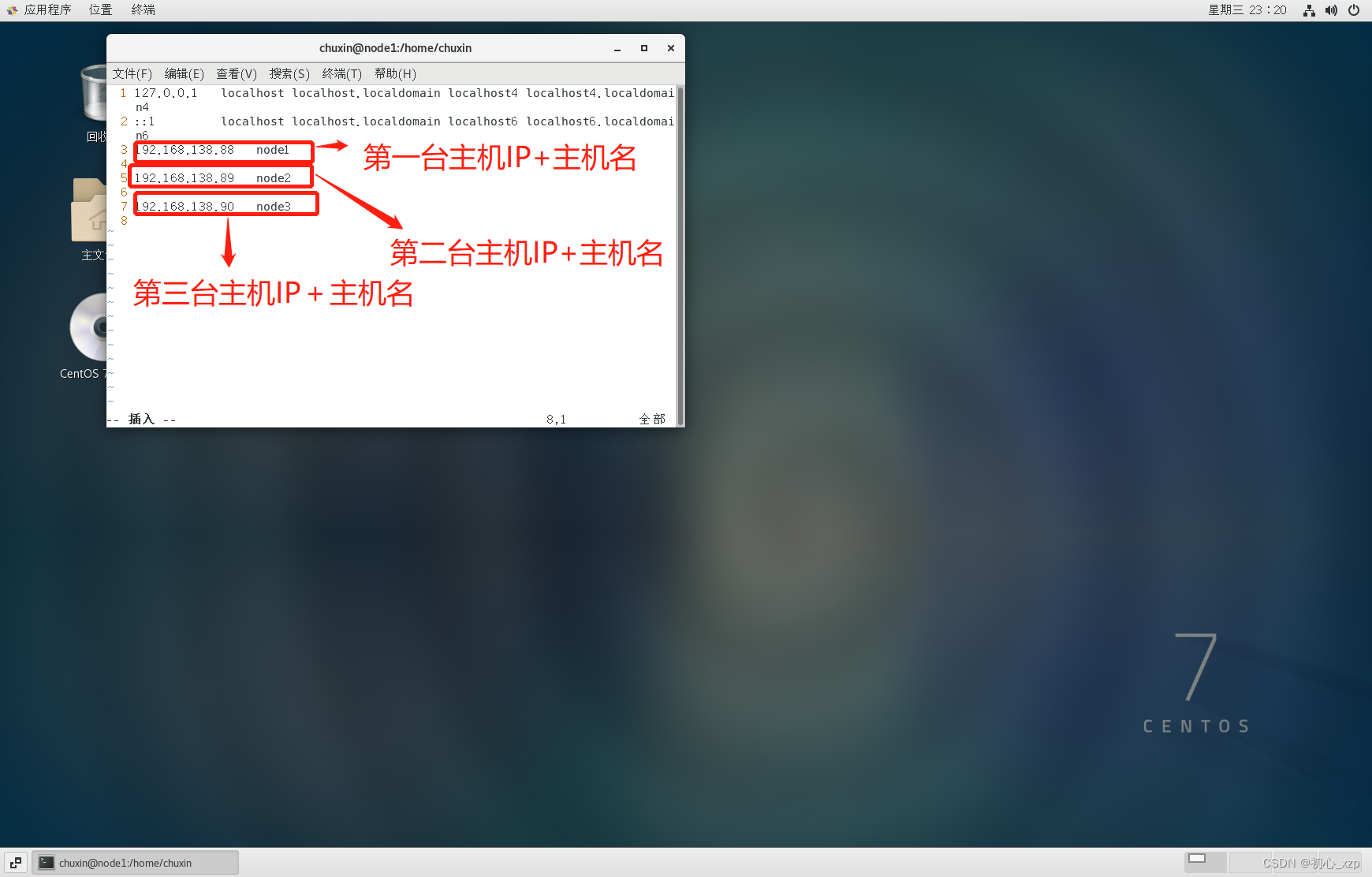
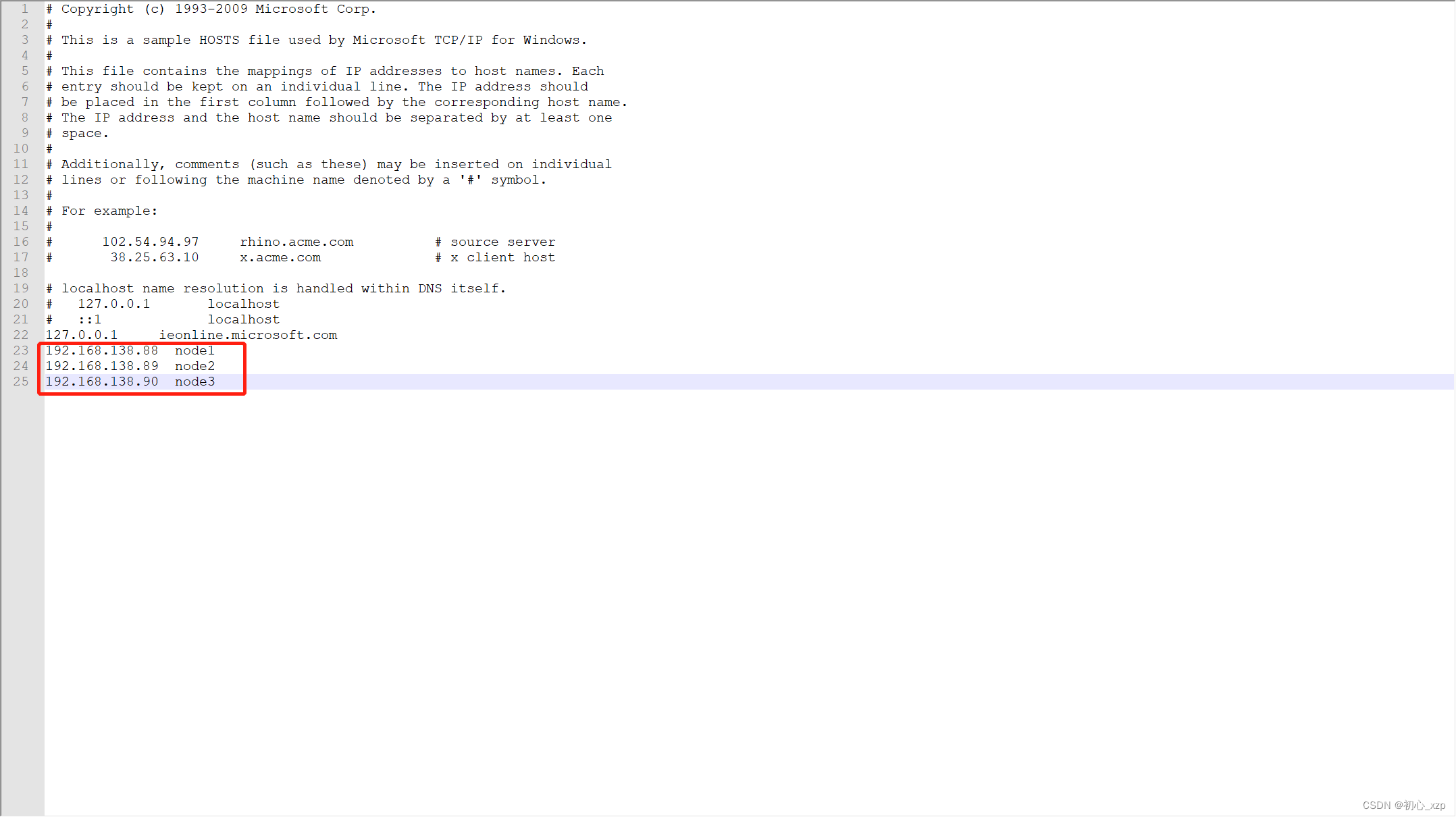
1.1hadoop完全分布搭建(建议用管理员权限启动虚拟机,防止出现权限不足或者lock等问题,在配置hadoop集群过程中建议切换到root用户下进行配置) 1.2修改主机名(这里修改为node1,也作为主机使用) hostnamectl set-hostname node1查看主机名 hostname配置主机名(如果忘记主机IP可以用ifconfig命令来查询),这里添加3台主机,另外两台主机配置内容也一样,都是这三个IP+主机名 vim /etc/hosts
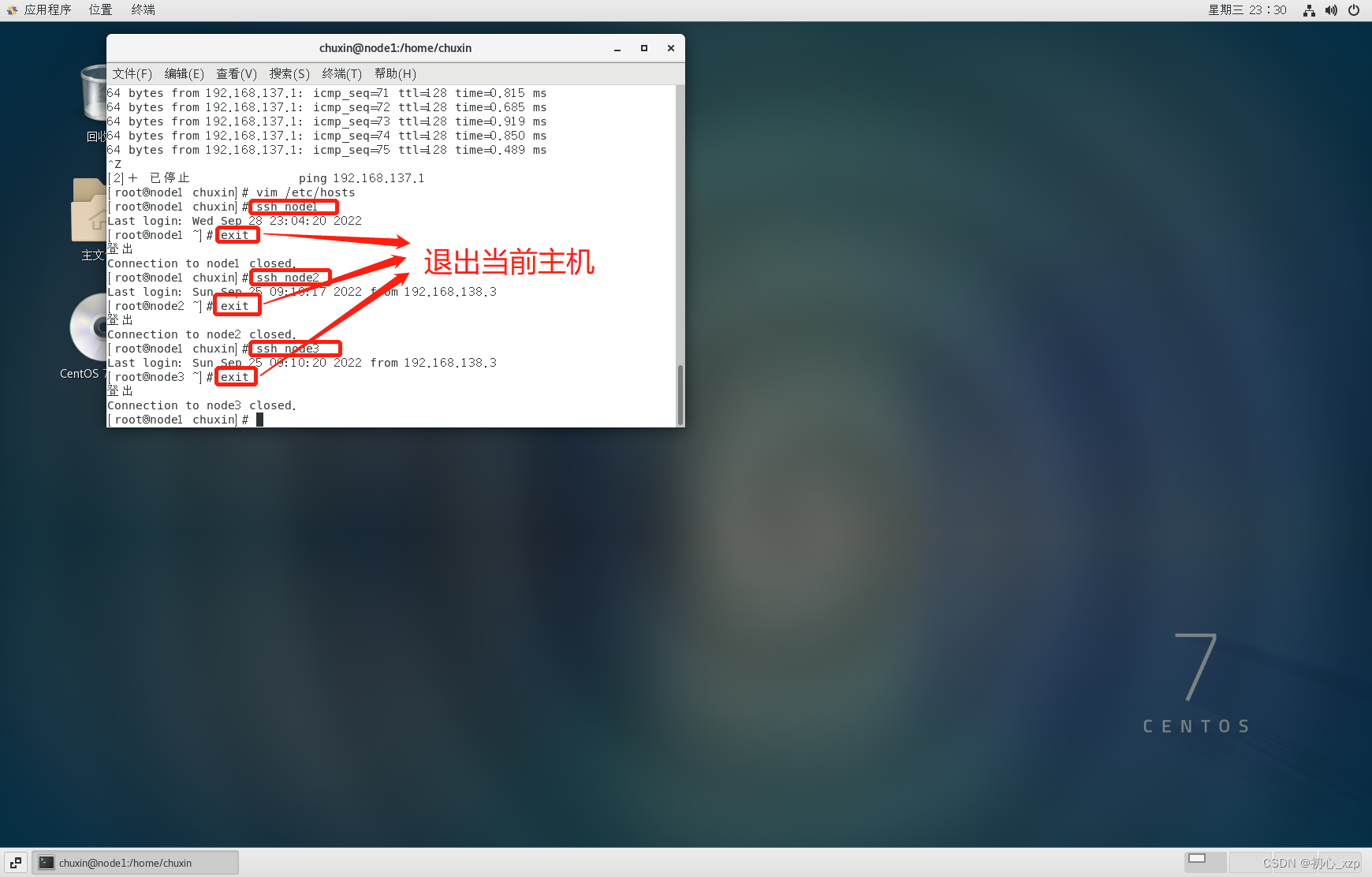
免密码登录配置(三台主机都按下面方法操作一遍) 执行 ssh-keygen -t rsa 按三次Enter键如果中途出现选择请选择yes 公钥追加到~/.ssh/authorized_keys文件中 ssh-copy-id -i ~/.ssh/id_rsa.pub 第一台主机名 ssh-copy-id -i ~/.ssh/id_rsa.pub 第二台主机名 ssh-copy-id -i ~/.ssh/id_rsa.pub 第三台主机名测试免密码登录三台都测试,当测试完一台后记得退出当前测试主机: ssh 主机名退出当前主机 exit
1.3安装jdk 1.31卸载原先的java jdk rpm -qa | grep java根据显存版本进行卸载操作 rpm -e --nodeps java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_641.32安装jdk 将jdk压缩包拷贝到虚拟机系统的一个目录上(这里拷贝到/usr/java下,一般来说usr目录下是没有java文件夹需要自己创建一个 (mkdir java)) 在java目录下进行解压压缩包 tar -zxvf 压缩包名称修改配置文件 vim ~/.bashrc在文件的最后添加下面的jdk信息 export JAVA_HOME=centos系统中的jdk路径 export CLASSPATH=$JAVA_HOME/lib/ export PATH=$PATH:$JAVA_HOME/bin export PATH JAVA_HOME CLASSPATH配置完成后执行下面代码使环境变量生效 source ~/.bashrc查看java版本 java -version将上面配置复制到其他两台主机 scp -r 复制文件路径 接收文件主机名:接收文件路径例如:scp -r /usr/java node1:/usr/ 1.33hadoop安装 进入hadoop压缩包目录 解压hadoop压缩包 tar -zxvf 压缩包名可创建文件软链接,简化配置 ln -s 解压后文件名 hadoop配置环境变量 vim ~/.bashrc在文件的最后添加下面的hadoop信息 export HADOOP_HOME=hadoop路径 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH配置完成后执行下面代码使环境变量生效 source ~/.bashrc总共要修改的配置文件全部都在hadoop/etc/hadoop目录下,其中hdfs-site.xml这个文件需要设置3个目录来存放一些hadoop运行过程中的临时数据,也就是在hadoop目录下,创建一个dfs和tmp,再在dfs目录下创建name和data目录。hadoop的八个配置文件中,有3个配置文件只需要修改jdk路径。分别是hadoop-env.sh,yarn-env.sh,mapred-env.sh。找到 export JAVA_HOME= , 等号后面改成centos系统中的jdk路径 即可。 当然,如果前面有#注释,可以把注释去掉(一般都没有注释)。 进入hadoop/etc/hadoop目录 1.34core-site.xml配置 执行 vim core-site.xml fs.defaultFS hdfs://node1:9000 io.file.buffer.size 131072 hadoop.tmp.dir file:hadoop中tmp路径 Abase for other temporary directories.1.35hdfs-site.xml配置 vim hdfs-site.xml dfs.namenode.secondary.http-address node2:9001 dfs.namenode.name.dir file:hadoop的dfs中的name文件夹路径 dfs.datanode.data.dir file:hadoop的dfs中的data文件夹路径 dfs.replication 3 dfs.webhdfs.enabled true
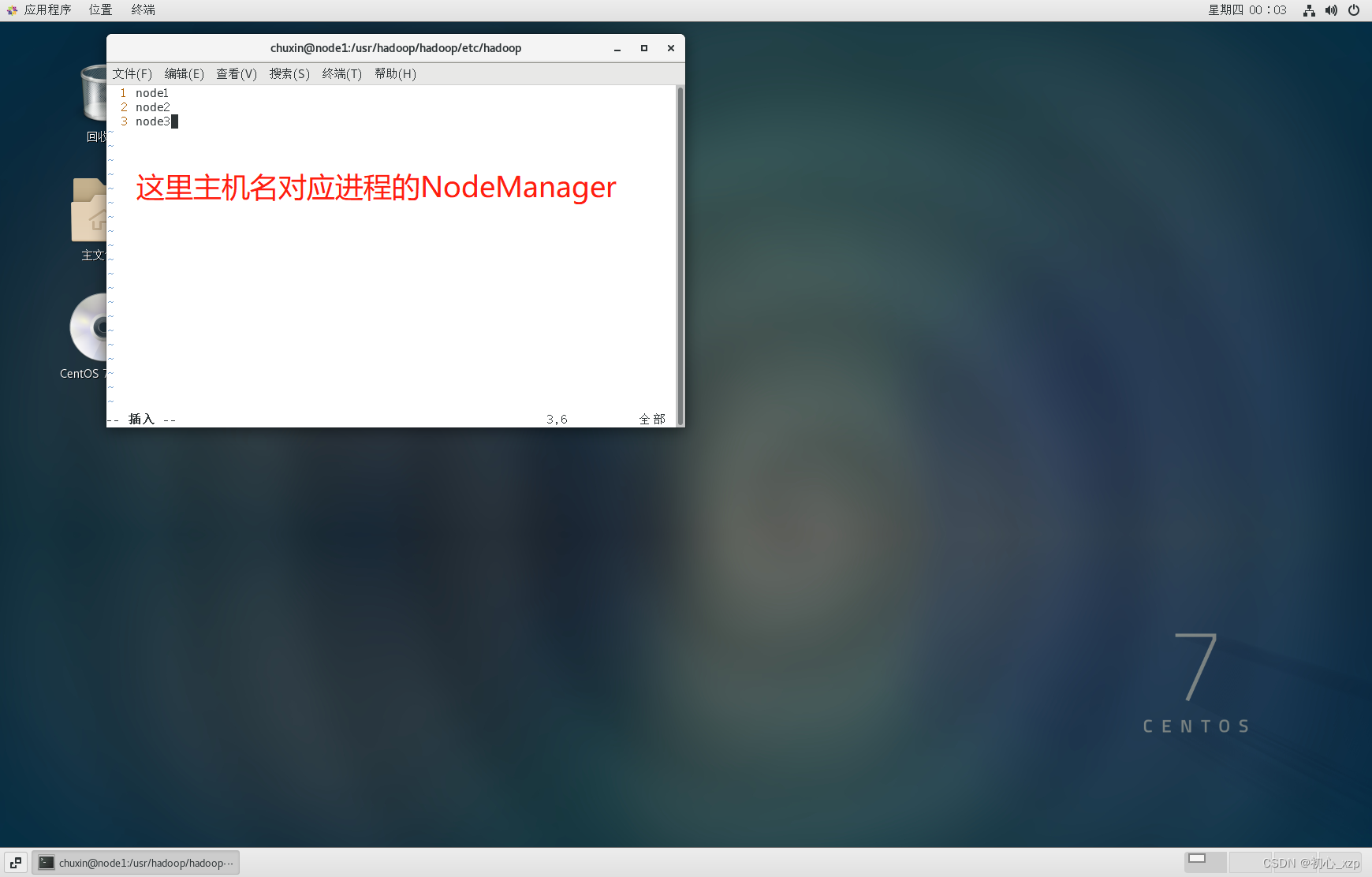
1.36配置mapred-site.xml 如果没有修改文件则执行 cp mapred-site.xml.template mapred-site.xml执行 vim mapred-site.xml mapreduce.framework.name yarn mapreduce.jobhistory.address node1:10020 mapreduce.jobhistory.webapp.address node1:198881.37配置yarn-site.xml 执行 vim yarn-site.xml yarn.nodemanager.resource.memory-mb 1024 yarn.nodemanager.resource.cpu-vcores 1 yarn.resourcemanager.hostname node1 yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.env-whitelist JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.resourcemanager.address node1:8032 yarn.resourcemanager.scheduler.address node1:8030 yarn.resourcemanager.resource-tracker.address node1:8031 yarn.resourcemanager.admin.address node1:8033 yarn.resourcemanager.webapp.address node1:80881.38配置workers 执行 vim workers 第一台主机名 第二台主机名 第三台主机名
1.39格式化 hdfs namenode -format1.40将上面配置复制到其他两台主机 scp -r 复制文件路径 接收文件主机名:接收文件路径例如:scp -r /usr/hadoop node1:/usr/ 1.41启动停止Hadoop的环境(只需在主机上启动即可,另外两台主机会跟着启动) start-all.sh stop-all.sh1.42查看进程 jps2.1Zookeeper集群搭建 进入zookeeper压缩包目录 解压zookeeper压缩包 tar -zxvf 压缩包名可创建文件软链接,简化配置 ln -s 解压后文件名 zookeeper进入zookeeper文件夹,创建tmp文件夹 mkdir tmp配置环境变量 vim ~/.bashrc在文件的最后添加下面的zookeeper信息 export ZOOKEEPER_HOME=zookeeper文件路径 export PATH=$ZOOKEEPER_HOME/bin:$PATH配置完成后执行下面代码使环境变量生效 source ~/.bashrcZooKeeper的核心服务器属性配置文件是zoo.cfg。在主安装目录下的conf子目录内,系统为用户准备了一个模板文件zoo_sample.cfg,我们可以将这个文件拷贝一份,命名为zoo.cfg,然后修改配置文件。首先我们进入到conf子目录,执行以下命令: cp zoo_sample.cfg zoo.cfg vim zoo.cfg #tickTime:CS通信心跳时间 tickTime=2000 #initLimit:LF初始通信时限 initLimit=5 #syncLimit:LF同步通信时限 syncLimit=2 #dataDir:数据文件目录 dataDir=zookeeper中tmp文件路径,tmp文件夹需要自己在zookeeper文件夹中创建 #clientPort:客户端连接端口 clientPort=2181 #服务器名称与地址:集群信息(服务器编号,服务器地址,LF通信端口,选举端口) server.1=node1:2888:3888 server.2=node2:2888:3888 server.3=node3:2888:3888在zookeeper中tmp下创建一个文件myid 进入zookeeper文件夹 vim myid在myid里面输入1 将上面配置复制到其他两台主机 scp -r 复制文件路径 接收文件主机名:接收文件路径例如:scp -r /usr/zookeeper node1:/usr/ 复制完成后一定要修改另外两台机的myid 修改第二台主机的myid,改为2 修改第三台主机的myid,改为3 启动 分别在每台机器上运行zkServer.sh start命令 zkServer.sh start查看状态 运行 zkServer.sh status有一台显示:Mode: leader,其他机器显示:Mode: follower。 3.1Hbase集群搭建 进入Hbase压缩包目录 解压Hbase压缩包 tar -zxvf 压缩包名可创建文件软链接,简化配置 ln -s 解压后文件名 hbase创建zookeeper数据目录 进入hbase文件夹 mkdir zookeeper配置环境变量 vim ~/.bashrc在文件的最后添加下面的Hbase信息 export HBASE_HOME=hbase文件夹路径 export PATH=$HBASE_HOME/bin:$PATH配置完成后执行下面代码使环境变量生效 source ~/.bashrc修改配置文件hbase-env.sh 进入hbase的conf文件夹 vim hbase-env.sh在打开的文件中,找到“# export JAVA_HOME”开头的文件,去掉前面的“#”,修改为: export JAVA_HOME=jdk文件路径另外,找到“# export HBASE_MANAGES_ZK”开头的文件,去掉前面的“#”,修改为: export HBASE_MANAGES_ZK=true再修改配置文件hbase-site.xml vim hbase-site.xml hbase.rootdir hdfs://node1:9000/hbase hbase.cluster.distributed true hbase.zookeeper.quorum node1,node2,node3 dfs.replication 2 hbase.master.maxclockskew 180000 hbase.zookeeper.property.dataDir hbase中zookeeper文件路径(若没有zookeeper文件夹则在hbase文件夹中自己创建)修改配置文件regionservers vim regionservers在打开的文件中,将里面的内容修改为: node1 node2 node3再在另外两台机器执行上面同样的操作,或在第一台机器执行下面命令,将hbase目录拷贝过去。 scp -r 复制文件路径 接收文件主机名:接收文件路径启动Hbase start-hbase.sh查看进程 jps4.1Eclipse调用HBase集群安装配置 打开Eclipse软件 --> 新建Java项目(File --> New --> Other --> Java Project --> 输入项目名称)(这里是HBaseBasic) 导入jar包 新建文件夹lib,右击项目 --> New --> Folder --> 输入文件夹名称“lib” 将hbase的lib目录下所有jar包放到lib下 右键项目根目录,选择 “Properties”->“Java Build Path”->“Library”->“Add External JARs”,将lib子目录下所有jar 包添加到本工程的Classpath下 完成上述操作后刷新一下 添加hbase-site.xml 右击项目名 --> New --> Source Folder --> 输入项目名称,这里取名为conf 将虚拟机集群上配置的hbase-site.xml文件复制到conf目录下 修改hosts文件(存放位置:C:\Windows\System32\drivers\etc) 添加如下内容(Note:ip和主机名根据集群上的配置做出相应的修改。) IP+虚拟机主机名 例如: 192.168.138.88 node1 192.168.138.89 node2 192.168.138.90 node3
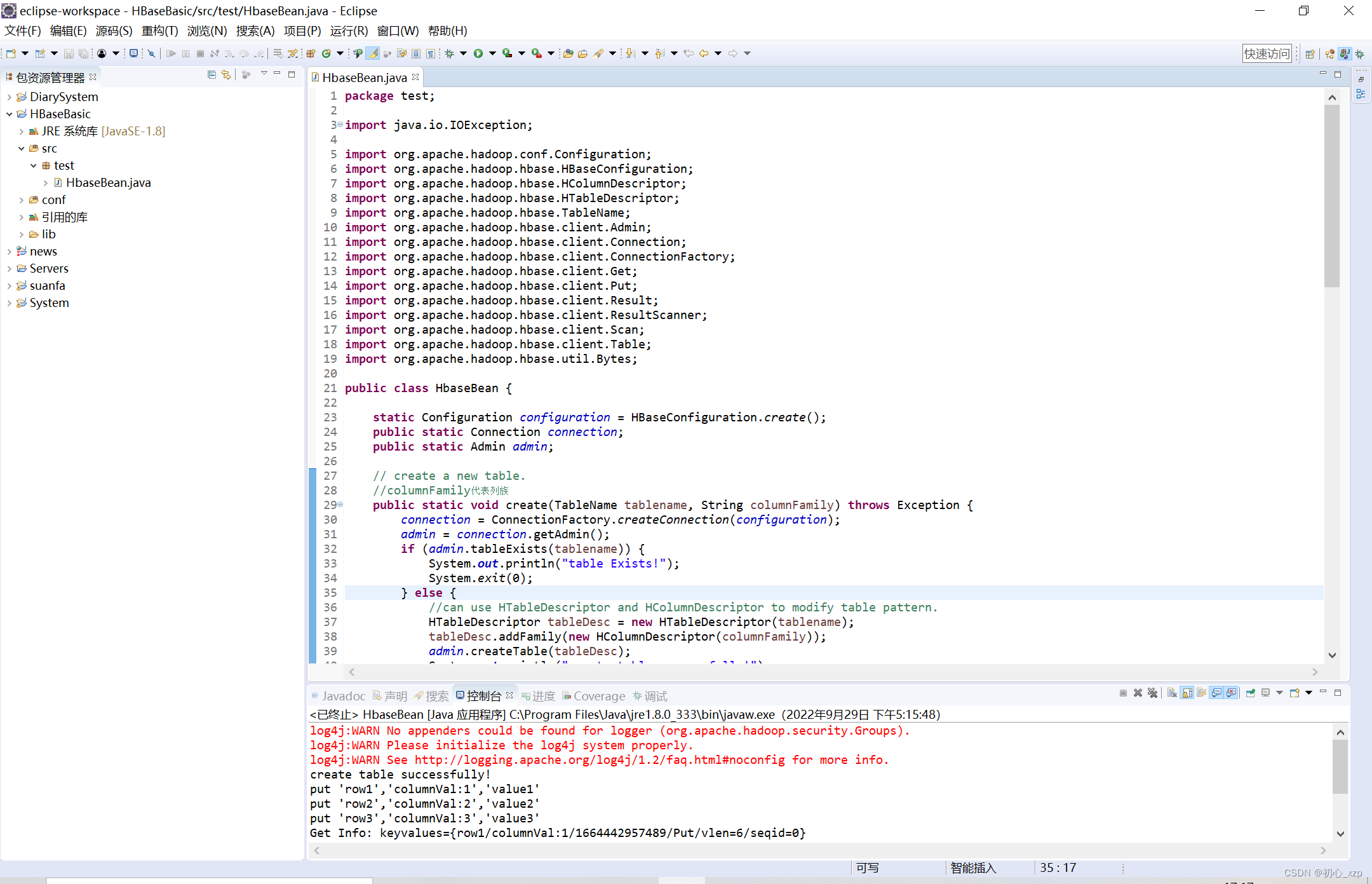
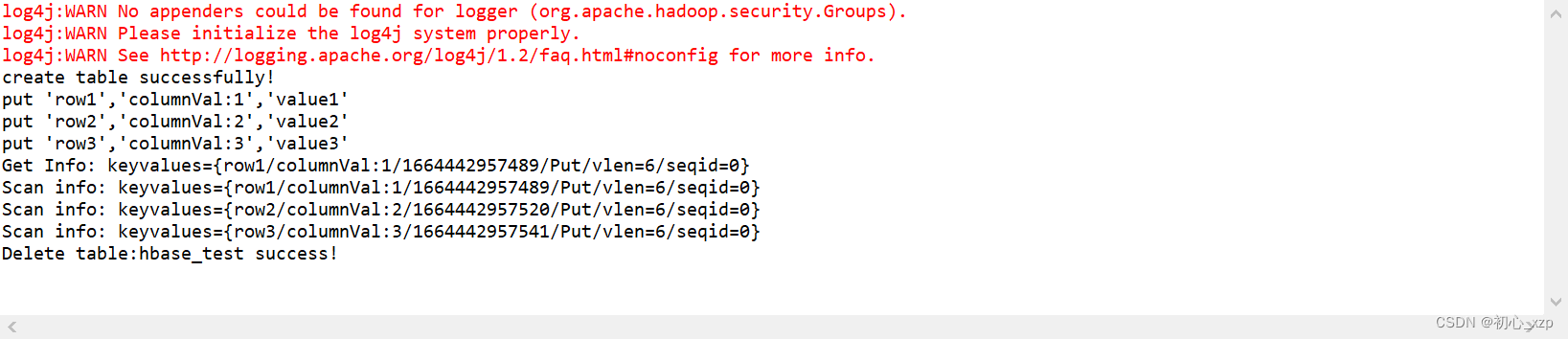
注:如何是window10或window11的用户请把hosts这个文件拉出来修改,待修改完后再拉进去替换。 测试(类这里命名为HbaseBean.java) 在Eclipse创建的项目中的src里面创建一个java类文件(后缀名为.java的文件)在文件中添加如下内容: package test; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Admin; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Get; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.ResultScanner; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.client.Table; import org.apache.hadoop.hbase.util.Bytes; public class HbaseBean { static Configuration configuration = HBaseConfiguration.create(); public static Connection connection; public static Admin admin; // create a new table. //columnFamily代表列族 public static void create(TableName tablename, String columnFamily) throws Exception { connection = ConnectionFactory.createConnection(configuration); admin = connection.getAdmin(); if (admin.tableExists(tablename)) { System.out.println("table Exists!"); System.exit(0); } else { //can use HTableDescriptor and HColumnDescriptor to modify table pattern. HTableDescriptor tableDesc = new HTableDescriptor(tablename); tableDesc.addFamily(new HColumnDescriptor(columnFamily)); admin.createTable(tableDesc); System.out.println("create table successfully!"); } } // insert a record. public static void put(TableName tablename, String row, String columnFamily, String column, String data) throws Exception { connection = ConnectionFactory.createConnection(configuration); Table table = connection.getTable(tablename); Put p = new Put(Bytes.toBytes(row)); p.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(data)); table.put(p); System.out.println("put '" + row + "','" + columnFamily + ":" + column + "','" + data + "'"); } // get data of some row for one table. // which equals to hbase shell command of " get 'tablename','rowname' " public static void get(TableName tablename, String row) throws IOException { connection = ConnectionFactory.createConnection(configuration); Table table = connection.getTable(tablename); Get g = new Get(Bytes.toBytes(row)); Result result = table.get(g); System.out.println("Get Info: " + result); } // get all data of this table, using "Scan" to operate. public static void scan(TableName tablename) throws Exception { connection = ConnectionFactory.createConnection(configuration); Table table = connection.getTable(tablename); Scan s = new Scan(); ResultScanner rs = table.getScanner(s); for (Result r : rs) { System.out.println("Scan info: " + r); } } // delete a table, this operation needs to disable table firstly and then delete it. public static boolean delete(TableName tablename) throws IOException { connection = ConnectionFactory.createConnection(configuration); admin = connection.getAdmin(); if (admin.tableExists(tablename)) { try { admin.disableTable(tablename); admin.deleteTable(tablename); } catch (Exception ex) { ex.printStackTrace(); return false; } } return true; } public static void main(String[] agrs) { TableName tablename = TableName.valueOf("hbase_test"); String columnFamily = "columnVal"; try { //Step1: create a new table named "hbase_test". HbaseBean.create(tablename, columnFamily); //Step2: insert 3 records. HbaseBean.put(tablename, "row1", columnFamily, "1", "value1"); HbaseBean.put(tablename, "row2", columnFamily, "2", "value2"); HbaseBean.put(tablename, "row3", columnFamily, "3", "value3"); //Step3: get value of row1. HbaseBean.get(tablename, "row1"); //Step4: scan the full table. HbaseBean.scan(tablename); //Step4: delete this table. if (HbaseBean.delete(tablename) == true) System.out.println("Delete table:" + tablename + " success!"); } catch (Exception e) { e.printStackTrace(); } } }在虚拟机主机中启动hadoop进程和hbase进程后运行上述代码。 结果:
运行结果为下图所示则证明配置成功
配置完成
|



 1.18选择Internet协议版本4(TPC/IPv4)
1.18选择Internet协议版本4(TPC/IPv4) 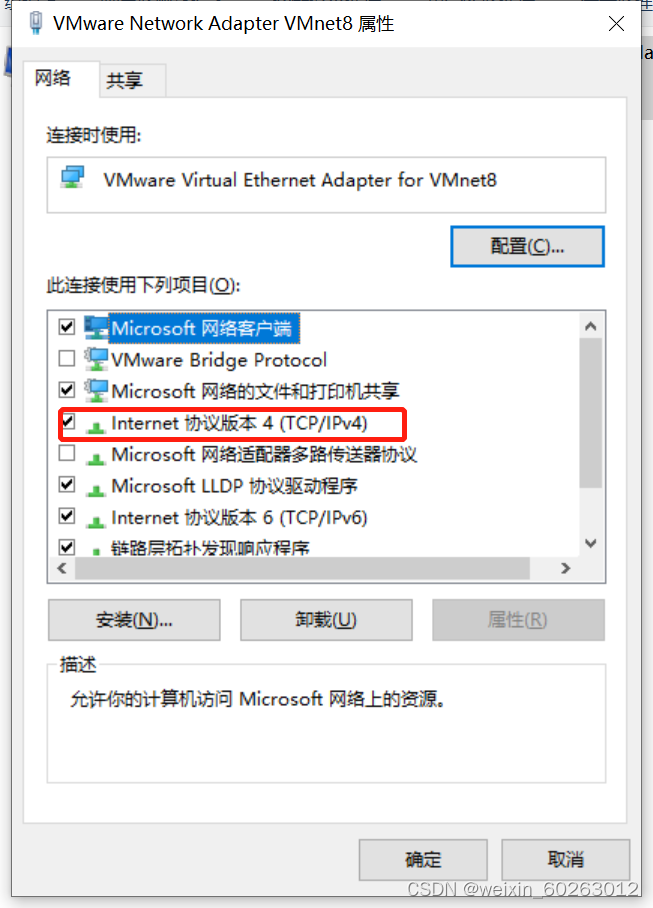




【本文地址】